Venturing beyond NLP and into intelligent document processing to tackle even more data related problems for our clients
You probably know of Eigen as an NLP provider, meaning that we answer questions and extract data from long strings of text like those found in contracts, emails, reports, etc. However, NLP or natural language processing by its very definition focuses only on the textual elements of a document, whereas we at Eigen do so much more.
When a human looks at a document, they process not only the text-based written content within it but also the image cues it contains so they can amass as much information as possible. So earlier this year, we released additional functionality focused on image detection and object recognition: what we are calling a tables extraction module. The tables extraction module is being used by several of our clients who needed the capability to extract tables from documents such as syndicated loan agreements, annual reports, SEC filings, private equity quarterly reports, etc.
This has been an extremely exciting release for us as we’ve been able to develop a solution to a critical problem for existing and new clients that has also moved us into new territory. So much so that we’ve had to redefine who we are as a company. Previously I would often refer to Eigen as an NLP company, but the reality is we’re no longer just an NLP company. We’ve developed one of the most sophisticated, and easy to use, tables detection and extraction AI solutions in the market, leveraging extensive research in the image recognition and object detection space. I can no longer say we’re an NLP company, but rather we tackle the problems of leveraging unstructured and semi-structured data more generally deepening our commitment to helping organizations make their data useful. We’re an intelligent document processing (IDP) company.
Now I’ve told you how this recent product development had me grappling with our identity, let me explain to you how the tables extraction module works. You simply upload all your documents – for example, annual reports, medical documents, bank statements, quality control reports, bond prospectuses or even newspaper articles. You can upload these documents either manually or automate the process using our APIs. The Eigen platform then gets to work recognizing and detecting tables from an image of the pages within the document This field of AI and machine learning is called computer vision and enables object detection, with tables being the object in question in this case.
Eigen uses computer vision, object detection and image classification in the same way that autonomous vehicles do. Self-driving cars detect and classify objects (such as traffic lights, pedestrians, other vehicles) accurately in real-time to safely steer through highways and cities. Eigen applies these same deep learning methods to recognize tables, classify them accordingly and extract all the data from within them to help organizations effectively navigate complex documents and datasets.
Surely tables extraction is easy? Most data scientists would argue otherwise. Remember not all tables have simple, straight lines and some have no lines at all to denote their boundaries. The platform therefore must be ‘intelligent’ enough to figure out where the implied lines should be and virtually draw them in. It can then extract the table along with the structure of the table and its contents into whatever format you require: Excel, HTML, JSON etc. The diagram below shows the steps in the table extraction process.
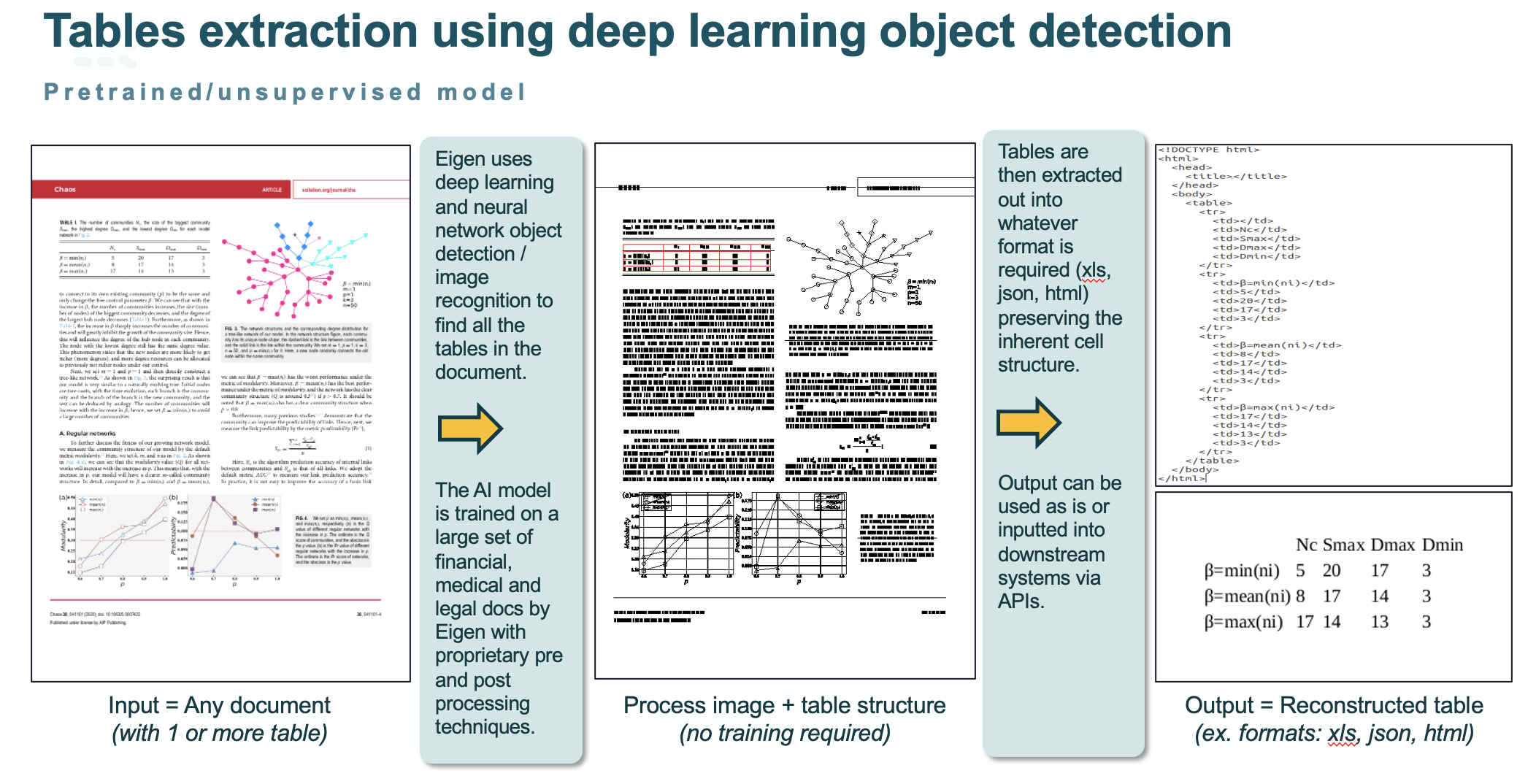
As this is a completely pre-trained and unsupervised model you don’t need any training to make it work. Our tables extraction module is readymade to add value the second it’s implemented – with no annotation or labelling required. Using deep learning, we have pre-trained the platform on millions of documents spanning the medical, financial, legal, industrial and academic sectors making it truly usable across any document and any table. What’s more exciting is that we have benchmarked our horizontally scalable platform and showed it to be the best general solution in the market performing on par with specific, more narrowly defined solutions that do require annotation.
And like everything we develop at Eigen, the module can not only be used out-of-the-box by any business user, but it can also be leveraged by developers and data scientists to deliver in-house custom AI solutions with a full suite of APIs and SDKs available too.
Does the complexity of your documents and datasets limit your ability to leverage the power of AI? Let us show you otherwise. Book some time with our team of experts and let us show you how our intelligent document processing platform can handle your documents and meet your data needs. Request a demo today.
You may also like



-
World Economic forum 2020

-
Gartner Cool Vendor 2020

-
AI 100 2021

-
Lazard T100

-
FT Intelligent Business 2019

-
FT Intelligent Business 2020

-
CogX Awards 2019

-
CogX Awards 2021

-
Ai BreakThrough Award 2022

-
CogX Awards Best AI Product in Insurance

-
FStech 2023 awards shortlisted

-
ISO27001

-
ISO22301

-
ISO27701

-
ISO27017

-
ISO27018
