ML Ops for Enterprise Machine Learning Platform Buyers
By Martin Staniforth – Technical Product Director at Eigen Technologies
Enterprise machine learning (ML) platform buyers often need to navigate a tricky terrain of new concepts in deeply technical domains. One such aspect, which has become critical to the success of corporate ML projects, is “ML Ops”. In this blog, I demystify the field so you can make informed decisions as you bring AI to your business.
It’s not often that the process used to build a product becomes as famous as the product itself. Henry Ford gave the world the moving assembly line. Ford’s 1913 automobile assembly plant provided each employee a clear division of labour, and a product that was moved to the worker for maximum efficiency. The moving assembly line reduced the time to build a Model T Automobile to just 93 minutes, quicker than it took to dry the car’s paint! The impact to the American economy was enormous as the new affordability of cars spawned a generation of road-building civil engineers, insurers, mechanics, travelling salespeople and many, many more dependent professions.
The ML Industry is currently aligning on a preferred process for managing the machine learning model lifecycle, which will be just as transformative as Henry Ford’s moving assembly line. This nascent field is called ML Ops.
What is ML Ops
ML Ops is at the intersection of machine learning and engineering - two complex domains - which can make the field seem inaccessible to executives tasked with sponsoring machine learning projects. However, understanding the importance of ML Ops is vital to the success of corporate initiatives for machine learning.
According to Gartner, 85% of machine learning projects fail to deliver, and only 53% of projects make it from prototype to production. ML Ops is designed to mitigate some of this risk and so should be considered as important as the algorithms used to solve those problems. Fortunately, once you cut through the many technical definitions, the concepts are fairly intuitive. There is no single approach to ML Ops but to keep things simple you can consider three core phases to managing the machine learning model lifecycle (see figure 1 below).
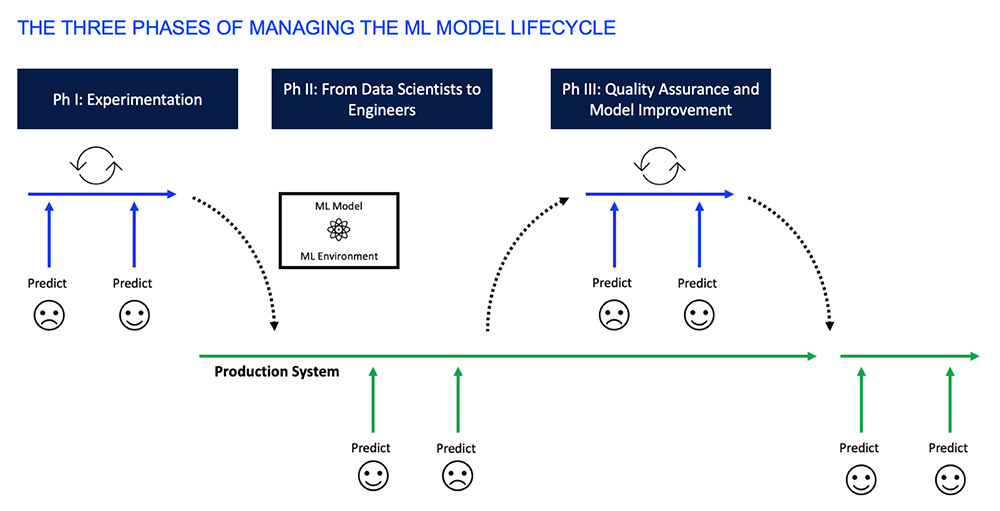
Phase 1 - Experimentation
Building ML models is an exploratory process. You can’t tell from the outset if an algorithm or approach will yield positive results. Data scientists will approach their problems in the same way as any scientist – through experimentation. Their goal is to learn from the 99 ways not to solve the problem in order to find the 100th approach that works.
During this phase, we want to give the data scientist all the tools they need to get from nothing to something. A machine learning model is cooked up from three ingredients. Code and Data are the two most people will be familiar with. The third is the slightly more esoteric term Environment.
In the world of open-source software, we’re all standing on the shoulders of giants. Environment refers to the libraries that our code depends on, the operating system and can also extend down to the microchips our code is run against. Change the code, the data or the environment and you could change the machine learning model. Like all scientists, we want our work to be reproducible, so managing these moving parts is imperative. We refer to these moving parts as “artifacts”, and their importance became apparent to Google engineers as they began their own ML Ops journey:
“An early realization we had was the following, artifacts are first class citizens in ML, on par with the processes that produce and consume them.” - Towards ML Engineering
We may need to merge datasets, revert to code without bugs, remove bad data, add more good data, try different algorithms, pre-process the data in a new way, try out new open-source libraries, and so on. Preserving the “artifact lineage” gives us a clear understanding of what state our artifacts were in for any given experiment. Experimentation and artifact management are key components of good ML Ops.
Phase 2 – From Data Scientists to Engineers
The next critical phase of ML Ops is to integrate our best ML models into a Production Environment. The last thing we want is for our data scientist’s R&D to die on the vine, and for all that hard work to fail to get into the hands of users. It may sound like this should be a formality but integrating ML models into a new or existing platform is surprisingly difficult. Ideally, you want to isolate the ML model from the rest of the platform. You don’t want to worry about your platform environment interfering with your ML model environment. Both components are also likely to evolve at a different pace and be worked on by different engineering teams, so separation becomes key. This phase of ML Ops is a much about people and process as it is about technology. The working environment should be as natural as it can be, with data scientists and Engineers working on a single “thing” but contributing their own unique skillsets.
The data scientist can focus on experimentation while the Engineer considers scalability, supportability, latency & throughput, data ingestion, integration with existing workflows and all the many other things engineers do, without having to reimplement all the work of the data scientist. Good ML Ops is about making this phase as efficient as possible so we can deliver a broader set of capabilities quickly.
Phase 3 – Quality Assurance and Model Improvement
Our ML model is now in a Production Environment and is delivering a huge amount of value to our users, but ML Ops doesn’t stop at the handover from data science to engineering. Our next concern should be that our ML Model continues to deliver value throughout its life.
In a Production Environment, our ML model will be exposed to far more data which may not have been available to us during experimentation, and there is potential to utilise this data to improve ML model performance. In heavily regulated environments, like banking, you may want strict control over using new data for model improvement. In less regulated industries, or for ML that improves platform usability, we can update models automatically through “continuous learning”. Either way, we’ll constantly be monitoring model quality with our ML Ops approach. One of thing to look out for is “data-drift”, where the data we originally used in the experimentation phase is no longer representative of what’s being seen in the real-world. A good ML solution will spend most of its life in this phase, so you want your ML Ops to make quality assurance and model improvement a breeze.
I hope this introduction to ML Ops has shed some light on the subject. Visit the Platform page for more information about Eigen.
You may also like



-
World Economic forum 2020

-
Gartner Cool Vendor 2020

-
AI 100 2021

-
Lazard T100

-
FT Intelligent Business 2019

-
FT Intelligent Business 2020

-
CogX Awards 2019

-
CogX Awards 2021

-
Ai BreakThrough Award 2022

-
CogX Awards Best AI Product in Insurance

-
FStech 2023 awards shortlisted

-
ISO27001

-
ISO22301

-
ISO27701

-
ISO27017

-
ISO27018
