No-Code RAG: How to Access and Chat with Unstructured Data
By Eugene Matskin - Solutions Consultant at Eigen Technologies
Prior to the end of 2022, document understanding vendors fundamentally existed the same. We competed on a per document type basis for the highest accuracy in hopes of proving our AI supremacy and applicability. Each win would further solidify a vendor’s niche until eventually, they could raise money based on the size of the problem their tool solved. The idea was obviously to prove product-market fit before expanding to other document types. Almost every tool in the market grew the same way and encountered the same problem: building horizontally while simultaneously satisfying investor demands is hard. It’s hard because every industry, line of business and business process consumes a high variation of documents, and each of their ideal solutions has very different needs. This has immense implications on how you, as a business, go to market and develop your product.
Shifting Paradigms in Intelligent Document Processing
If you’ve been in Intelligent Document Processing (IDP) long enough, you may already be familiar with the many different approaches vendors took to try to become a technology leader in IDP:
- Pre-trained models
- No-code fine-tuning platforms
- Industry-specific end-to-end solutions
In the end, AI supremacy as a competitive advantage became obsolete. Instead, the focus to become a product-first organization took center stage. With innovation rapidly seeping out of OpenAI, Google, Anthropic, etc., the future of IDP became less about intelligence and more about data quality. As such, these companies focused on the next evolution of IDP, building scalable chat agents that would allow users to interact with their entire repository of unstructured data.
Optimizing Large Language Models with RAG Architecture
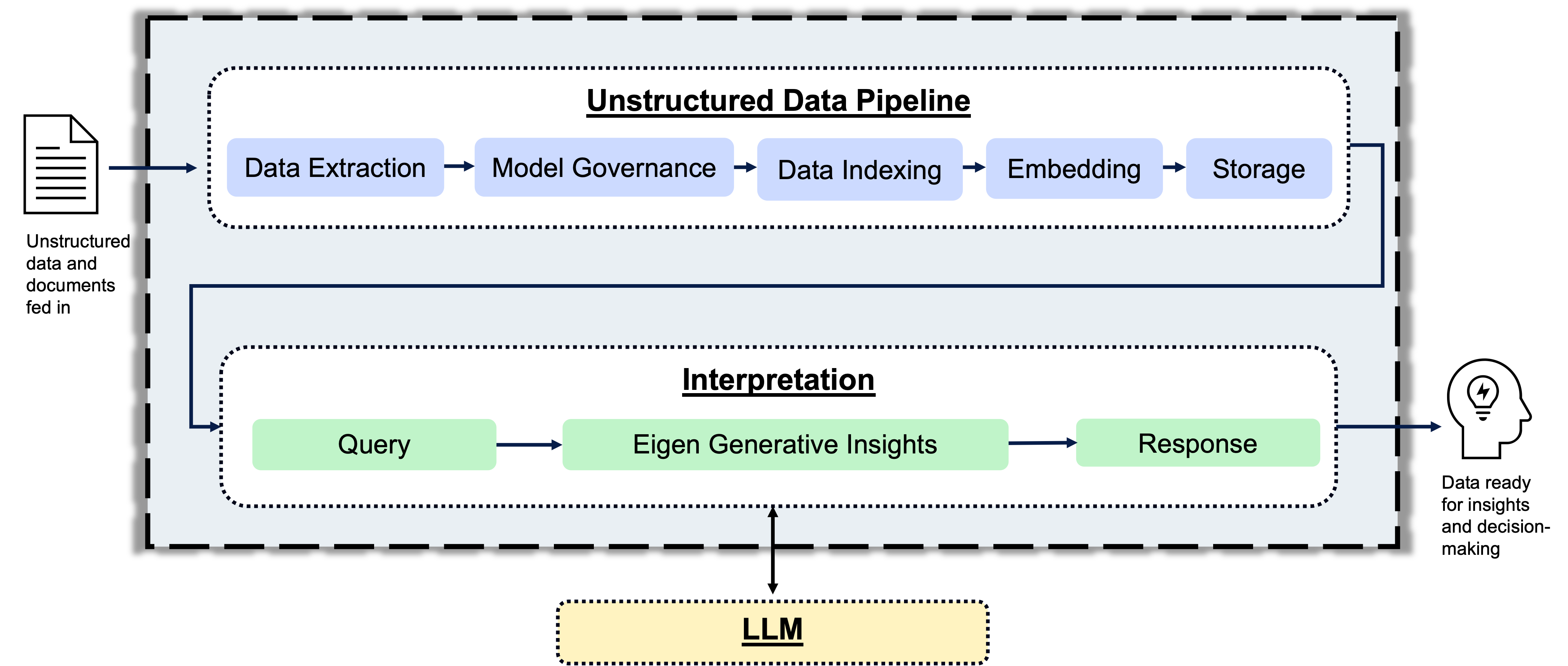
If you’ve concluded that accessing and chatting with unstructured data will enable your organization, a well-defined Retrieval Augmented Generation (RAG) framework can help you realize your vision. RAG architecture was created to optimize the performance of large language models (LLMs) by pipelining relevant data to the model when prompted by a user.
Here’s an example – a big bank wants to know what contracts are affected by a new regulation.
An LLM operating without RAG has two major constraints:
- Hallucinations – incorrect or irrelevant responses are returned due to the model’s inherent problems simultaneously processing the amount of source content and properly understanding its context.
- Token Consumption – since LLM usage is token-based, each contract will consume vast amounts of tokens as the model analyzes every character in each document.
In this example, the use of LLMs alone is not only expensive but also very risky, which is not acceptable for risk-averse clients like big banks.
An LLM with a well-constructed RAG architecture helps you avoid both constraints by:
- Determining what data is relevant to the query before feeding it into the LLM.
- Using relevant data vastly reduces the volume of content the LLM needs to consume.
Shaping the Future of Unstructured Data Processing
In this scenario (and thousands of other like it), the relevancy of the data becomes more important than the accuracy of the data extraction because LLMs have democratized accuracy when LLMs are provided with contextually relevant data. This is the future of IDP, and ultimately the future of all unstructured data processing. The adage, “Garbage in, Garbage out,” comes to mind.
To successfully empower your users with an unstructured data chat agent, organizations need to construct databases that store highly relevant and organized data. This ensures your RAG architecture will produce correct results.
Before LLMs, Eigen positioned itself as a no-code fine-tuning solution. Today, Eigen positions itself as a no-code RAG for documents. By leveraging a suite of proprietary Natural Language Processing (NLP) and computer vision models to drive information retrieval in concert with LLMs, Eigen enables users to chat with their documents at scale. Eigen is perfectly suited to empower your AI strategy by helping you accomplish two things:
- Build relevancy in your document-based data while reducing risk and cost.
- Complete your RAG vision by offering a true no-code end-to-end document processing solution that accurately and affordably optimizes LLM performance.
If you are interested in learning more, don't miss Eigen's CEO dig into the details in Eigen's webinar, From Data to Decisions: Empowering Enterprises with LLMs and Gen AI.

You may also like


-
World Economic forum 2020

-
Gartner Cool Vendor 2020

-
AI 100 2021

-
Lazard T100

-
FT Intelligent Business 2019

-
FT Intelligent Business 2020

-
CogX Awards 2019

-
CogX Awards 2021

-
Ai BreakThrough Award 2022

-
CogX Awards Best AI Product in Insurance

-
FStech 2023 awards shortlisted

-
ISO27001

-
ISO22301

-
ISO27701

-
ISO27017

-
ISO27018
