Large Language Models (Part 3 of 3): How can Intelligent Document Processing Leverage the ChatGPT Revolution?
Blog Part 3: Making LLMs work in the Real IDP World – Technical Challenges and Key Risks
By Dr Lewis Z Liu – Co-founder and CEO at Eigen Technologies
In this final instalment of our blog series, we dig into the practicalities and risks relating to the use of LLMs for IDP including model governance and data privacy.
If you need to catch up, part one of the blog series is available here, and part two is available here.
Looking at the task of data extraction for documents, it is tempting to upload the entire string of text into GPT-4 with a prompt like ‘<document text> In the text above, what is the [x]?’ If we do that and try to set a prompt of a document that is around ~100k words long (common length for complex financial documents like loan agreements), it will not work. Even with the new and improved GPT-4, there is still a 25k word limit. Obviously GPT-5 and beyond will provide advancements but even if you find an instance that can handle 100k words, the cost of LLMs scale quadratically so extrapolating OpenAI’s cost model, this could cost $14 per query. To put this into context, a London-based paralegal will charge around $10 per query. Eigen’s traditional point extraction has a compute cost of around $0.00014 per query to accomplish the same extraction task, and Eigen’s BERT-based Instant Answers has a compute cost of around $0.0042 per query. This cost problem associated with document length and these LLMs, can be mitigated through pre-processing models like information retrieval (IR). Diagram 1 below, shows how information retrieval models mitigate this challenge.
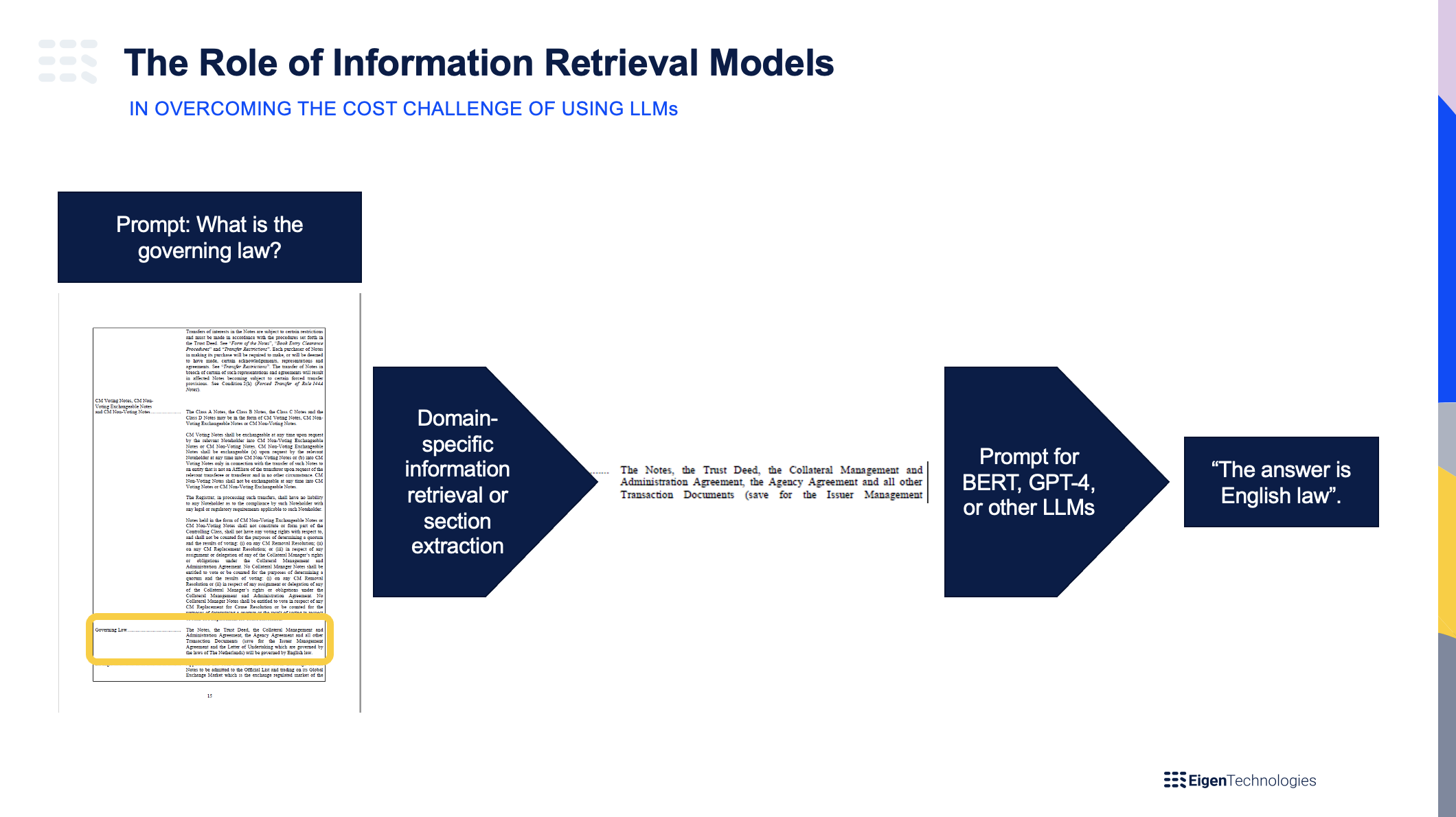
So, let’s say then that you have some other lightweight (hopefully also domain-specific) model that finds the relevant section of the document via information retrieval, and you provide the prompt for just that section. You potentially solve the length/cost problem, but now you run into the fact that OpenAI’s models are general and not domain-specific (or specific to the given use case). Moreover, it tends to pull from ‘general internet knowledge’ versus taking in the entire context of the document (as we just truncated the document to save on compute costs). In table 1 below, we highlight some of the key performance and accuracy challenges of using LLMs (such as GPT-4) out of the box and how to mitigate for them. Note: we’ll cover privacy and model governance separately in the next section as key risks that are harder to mitigate.
Challenge |
Details |
Mitigation Technique |
Word/token limit |
GPT-4 has a 32k token limit/25k word limit, which is enough for many use cases but not some of the high value use cases within finance, insurance, legal, etc. |
Leverage domain-specific information retrieval (IR) or section extraction (SE) techniques to partition the document into a smaller section to use as a prompt |
Compute or API costs |
LLMs are extremely computationally expensive (both in terms of time and money) and these costs scale quadratically the longer the prompt. |
IR and SE as above or consider using alterative frameworks if cost (money and/or time) is a key consideration |
Domain or Use Case Specificity |
Generic LLMs (BERT, GPT, etc) are trained on ‘general internet knowledge’ and not domain-specific documents, which can lead to substandard results |
Provide domain-specific fine-tuning to LLMs (using large, annotated datasets) or provide additional domain-specific rules on top of extraction results |
Generative models do not provide provenance |
Generative models (like GPT but not BERT) do not out of the box provide provenance of where the information was obtained, thereby increasing risk especially in highly- regulated use cases |
IR can help narrow down the sections to analyse by GPT; specific prompt engineering and string/coordinate matching is needed to enable this functionality |
Hallucination |
The LLM generates results outside the context of the prompt, providing false or nonsensical answers |
Tighter prompt engineering and IR and/or SE input generation |
Table 1: Performance and accuracy challenges of LLMs and how to mitigate for them
Key Risks Associated with using LLMs blindly
As mentioned in the previous section, two of the key risks that LLMs present when being used for document processing are model governance and IP/data privacy.
Model Governance
Most regulated companies such as banks, insurance companies, healthcare payors/providers have fairly involved machine learning (ML) model governance and model risk management processes. This is to prevent bias or inaccurate automated decisions or results being generated by their ML/AI models. Moreover, there is typically a stringent process to approve certain models for production.
In the world of IDP, understanding answer confidence, estimating accuracy rates pre-production, and ensuring a smooth flow of model governance metrics are communicated to the user are all key to successful production.
Unfortunately, LLMs by themselves do not provide a calibrated confidence score in terms of how accurate an answer might be. Hence, these LLMs need to be placed within the right infrastructure to ensure smooth productization and confidence calibration. At Eigen, we have developed a full model governance and human exception handling framework to ensure the maximization of accuracy and value with the minimization of model risk.
IP & Privacy
Regulated entities dealing with extra sensitive information such as banks, insurers, and healthcare companies cannot risk data leaked and integrated into the LLMs generated by OpenAI. JPMorgan Chase recently clamped down on the use of ChatGPT for compliance reasons according to a news report by CNN Business and the Italian government recently banned GPT on the basis of user privacy concerns.
The New York Times covered a story recently about a lawsuit involving the misuse of AI training data. The risk of leakage and misuse of training data for large-regulated entities could be existential for those institutions. Semiconductor engineers at Samsung unwittingly shared confidential data including source code for a new program when they used ChatGPT to help with some tasks.
Coming back to the world of IDP, at Eigen we process some of the most sensitive documents for institutions – both commercially and personally sensitive – including derivative contracts, detailed insurance claim reports, personal healthcare information, personal financial details, etc. As such, our entire company and infrastructure is set up to ensure that AI is leveraged safely; something we have invested significantly in since the foundation of our company.
While it is tempting to throw documents into GPT, there is a minefield of IP, privacy, and safety concerns to consider – and building the infrastructure to handle those is limited to only a small handful of IDP players, such as Eigen.
Game-changing advances in technology always bring about near hysteria about the revolutionary impacts, both positive and negative. Organizations with highly valuable information should always temper their excitement with the potential downside risks. There is a path to success but it's important not to ignore the path to failure.
It's hard to see how ChatGPT complies with current Privacy standards such as GDPR/CCPA and much more research is needed to understand how it meets these requirements. GCHQ advises users not to include sensitive information in queries or anything that could lead to issues if everyone saw their queries, when using AI bots like ChatGPT. The Telegraph reports that City firm Mishcon de Reya has banned its lawyers from typing client data into ChatGPT over security fears, as has Accenture. Organizations with highly valuable data should consider the impact on their organizational reputation of using these tools.
Security decisions need to be made based on understanding the risks and with emergent technology like this it is always a challenge to quantify the risk. It's not the right place to put your most valuable and sensitive data until we know significantly more than we do today. How would you explain to your clients and board the rationale for such a decision?
There is no doubt that LLMs and generative AI solutions like ChatGPT drive efficiencies and create opportunities for organizations in many new and exciting ways. To go back to our fighter jet analogy, in the world of IDP, they are a useful component to make the engine faster, more flexible, and more accurate dependent upon the use case(s) in question. But domain-specific fine-tuning, model risk management/governance and security controls are required to make LLMs fit for purpose when it comes to harnessing their power for document processing purposes. IDP specialists like Eigen, able to leverage LLMs in a compliant, cost-effective, and domain-relevant way, offer the best solution for enterprises looking to unlock data from documents using cutting-edge AI.
Learn how the Eigen IDP platform can be applied to a broad spectrum of use cases and document types by visiting our Solutions section or request a demo to see the platform in action for yourself.
You may also like


-
World Economic forum 2020

-
Gartner Cool Vendor 2020

-
AI 100 2021

-
Lazard T100

-
FT Intelligent Business 2019

-
FT Intelligent Business 2020

-
CogX Awards 2019

-
CogX Awards 2021

-
Ai BreakThrough Award 2022

-
CogX Awards Best AI Product in Insurance

-
FStech 2023 awards shortlisted

-
ISO27001

-
ISO22301

-
ISO27701

-
ISO27017

-
ISO27018
